Fifty-eight — LLM numerical IQ test
Some LLM-oriented IQ evaluations are already available on the Internet. For example, https://trackingai.org/home lists IQ-test results for well-known domestic and international LLMs, including the public Mensa Norway test and a private question set from a Mensa member. However, the Mensa Norway test is largely focused on visual reasoning. It may therefore also be useful to understand how LLMs perform on numerical reasoning.
Test Questions, Models, and Methodology
For this article, I chose the NUMERUS BASIC numerical reasoning test, which is less famous than Mensa (meaning it is probably less likely to have been absorbed into training data), yet still has some reference value: https://free.ultimaiq.net/numerus_basic.htm . I personally suspect that its scoring may be somewhat inflated, but it should still be useful for comparing the relative abilities of different LLMs.
I plan to evaluate the following models:
ChatGPT 5.3/5.4 Thinking (Standard, Extended)/5.4 Pro (Extended)(Web)Gemini 3 Flash/Thinking/3.1 Pro(Web)Claude Haiku 4.5 (Extended)(Web),Sonnet 4.6/Opus 4.6 Thinking(Antigravity)Grok 4.20 Fast/Expert(Web; Heavy is too expensive for me)Deepseek Instant (DeepThink)/Expert (DeepThink)(Web)Doubao Fast/Thinking/Expert(Web)Qwen3.5 Flash/Max/Max-Thinking(Web)
That is, a total of 20 different model configurations.
In order to balance the workload as much as possible while also giving each model the best chance to reach its upper bound, I adopted the following testing strategy:
- Send all 20 questions of NUMERUS BASIC in a single message and record the initial answers.
- For the second-round supplementary test, if a model got a question wrong, start a new conversation and resend those wrong questions one by one to obtain corrected answers.
- The prompt used was:
Please fill in the location of the question mark:
1) 1, 1, 1, 2, ?, 2
2) 1, 2, 4, 5, ?
3) -1, 5, 11, ?
4) 0.5, 2, ?, 32
5) 1, 3, 4, ?, 11
6) ?, 1, 3, 6, 10
7) 1, 10, 110, 1101, ?
8) 123, 354, 897, ?
9) 5, 10, 20, 35, ?
10) 2, 4, 12, ?, 72
11) 123, 451, ?, 512
12) 510001, 401010, 300200, ?
13) 11, 32, 54, 78, ?
14) 24, 16, 25, 66, ?, 36
15) 1/2, 3/4, 7/8, ?
16) 1/2, 3/2, 5/6, ?
17) 77, 49, 36, 18, ?
18) 135, 791, ?, 151
19) 138, 257, ?, 132
20) 123, ?, 789, 211101
Write your answers in a row using space to separate each other.
You CANNOT search the Internet, do these problems independently.
Initial Results
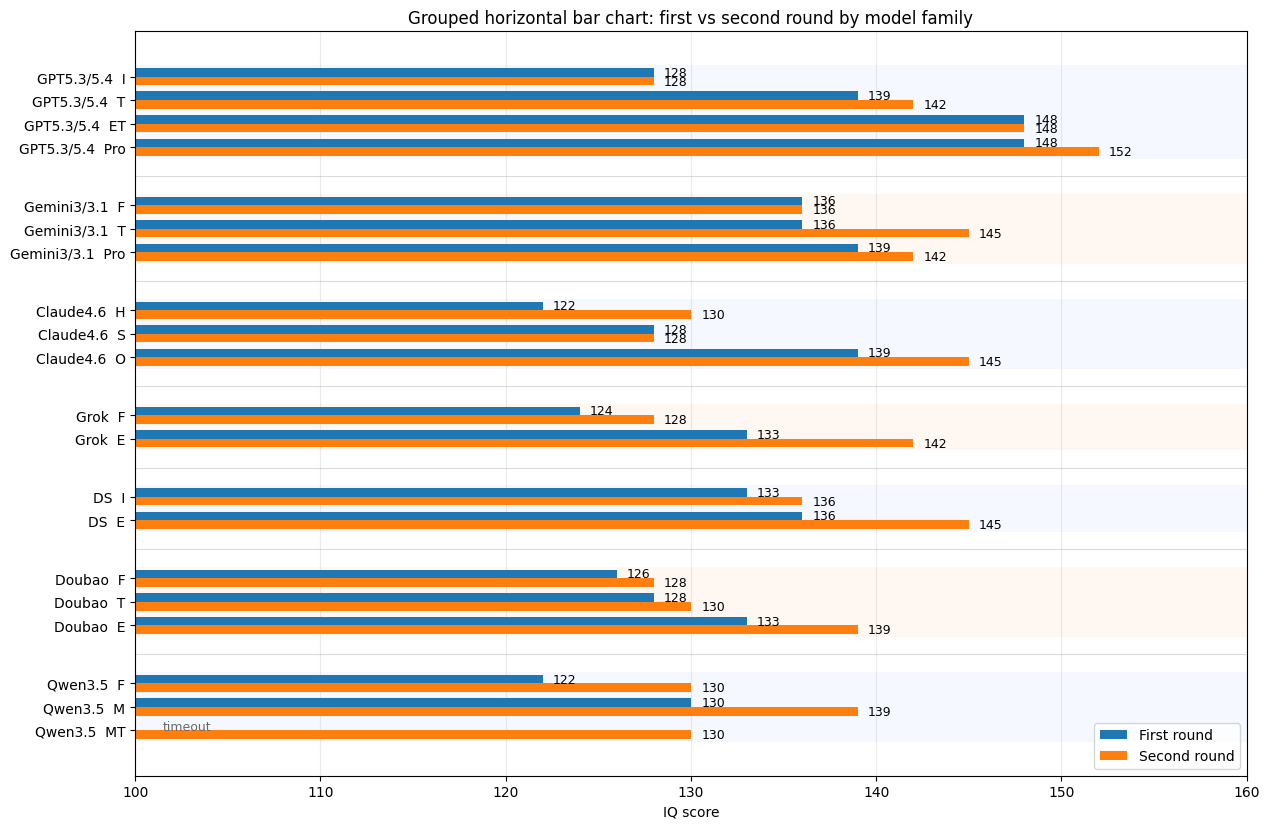
The first-round results are shown below:
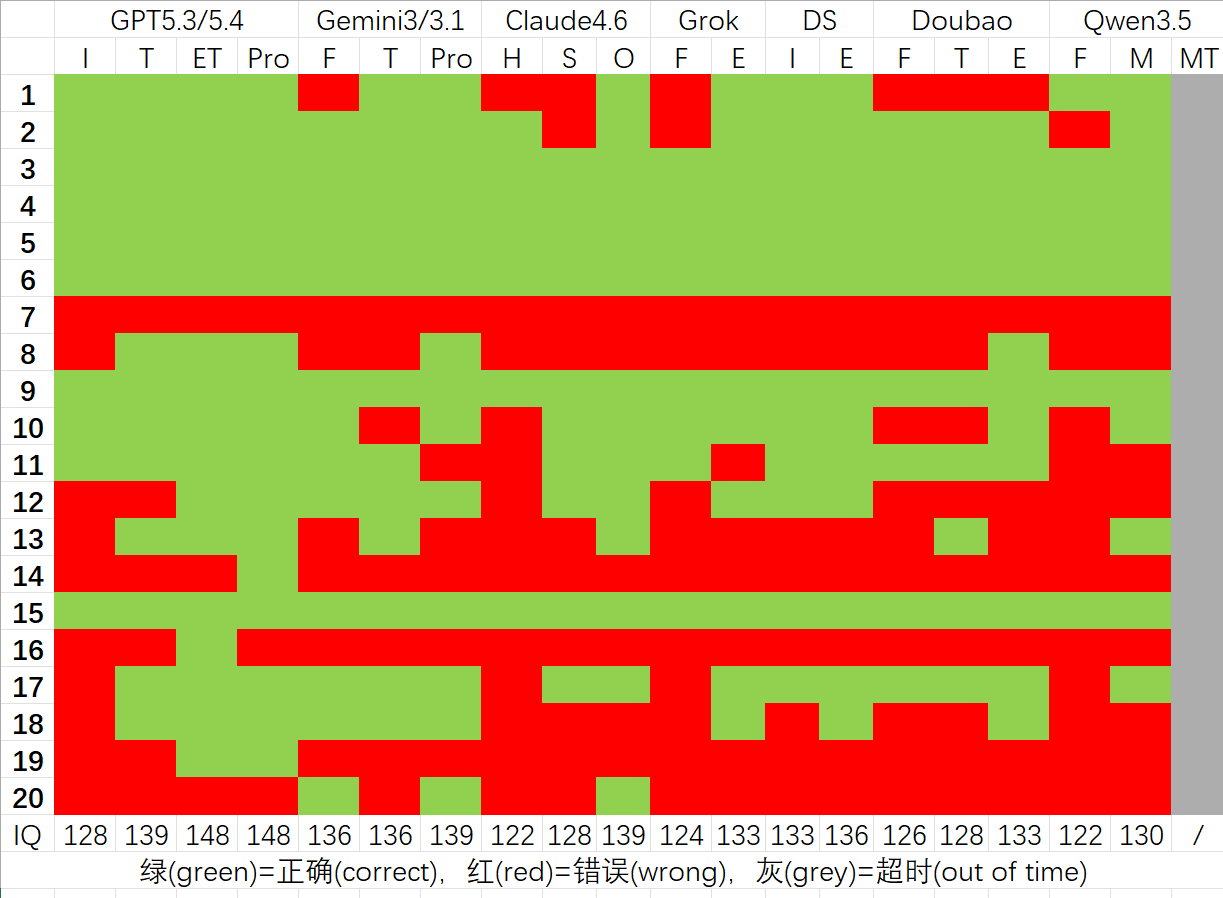
Several conclusions can be drawn:
- GPT leads all other LLMs by a cliff-like margin.
- Accuracy (IQ score) is positively correlated with thinking time.
- Among overseas models: GPT >> Gemini > Claude. Among Chinese models: Deepseek > Doubao > Qwen. Since I did not have access to the $300 Grok Heavy tier, direct comparison is difficult.
- Considering cost, Chinese LLMs are already largely competitive with overseas models, except for GPT.
There were also some interesting observations:
- The slowest model was Deepseek Expert with deep thinking enabled: all 20 questions took 4998 seconds in total.
- Qwen's system forcibly times out and interrupts the conversation after about 600 seconds of thinking, which is quite unfriendly; Deepseek, by contrast, offers a "continue" button, striking a better balance between inference cost and user experience.
- For LLMs, the hardest question was Question 7, whereas from a human perspective Question 14 is the hardest one (assuming you found that full-score explanation online).
- Qwen is not very honest: unless I repeatedly include the line
You CANNOT search the Internet, do these problems independently., it keeps trying to call a search engine.
Retest Results
The corrected second-round results are shown below, which I believe approximate the upper bound of each model's capability:
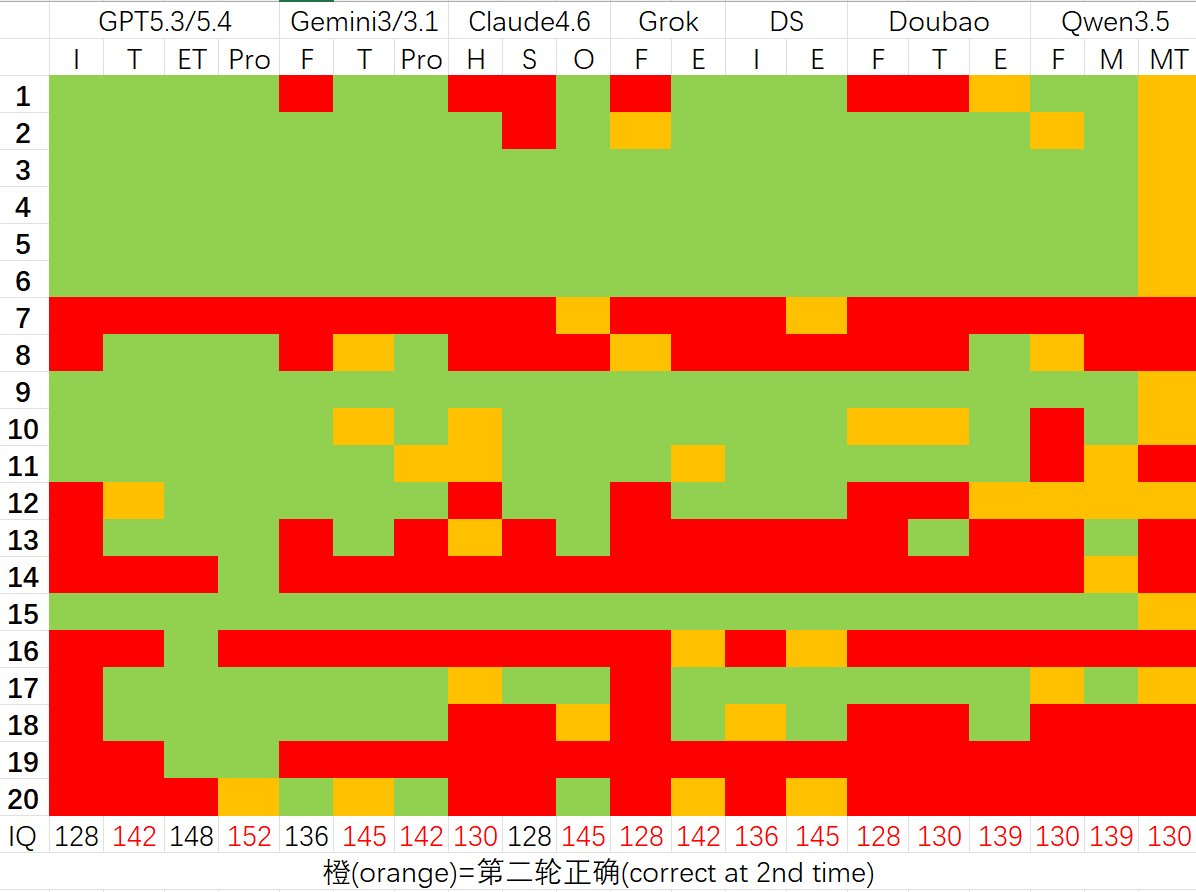
From these, we can conclude:
- GPT still leads all the other LLMs by a huge margin; the Pro version even exceeds 150 IQ.
- For most models, breaking the task apart is indeed beneficial for improving accuracy.
- Among overseas models: GPT >> Gemini > Claude. Among Chinese models: Deepseek > Doubao ≈ Qwen.
- Deepseek Expert has already reached the level of the best Gemini/Claude models — although its thinking time can be excessively long.
A few more interesting observations:
- Grok Fast seems to love spouting nonsense — which feels very much in line with Musk on drugs.

- While thinking about Question 14, Deepseek Expert (that is, the rumored V4 version) suddenly started reciting digits of pi. After waiting an entire afternoon, I took a random substring and checked it on this website to see whether it appeared within the first 2 billion digits of pi. The answer was no, which means Deepseek recited it incorrectly.

- Qwen Flash often likes to output repeating loops of text until the system forcibly stops it, which is oddly similar to the 600-second timeout behavior mentioned earlier.
- Qwen Max guessed the human-hardest Question 14 correctly using an incorrect line of reasoning.
- The answer to Question 13 is somewhat controversial. Many AIs point to another plausible answer, and that was actually my own first instinct as well. But in the interest of fairness, I scored it according to the official website's answer.
Visualizations
Comparison of all participating models before and after correction:
Comparison of the best-performing submodel in each family before and after correction:
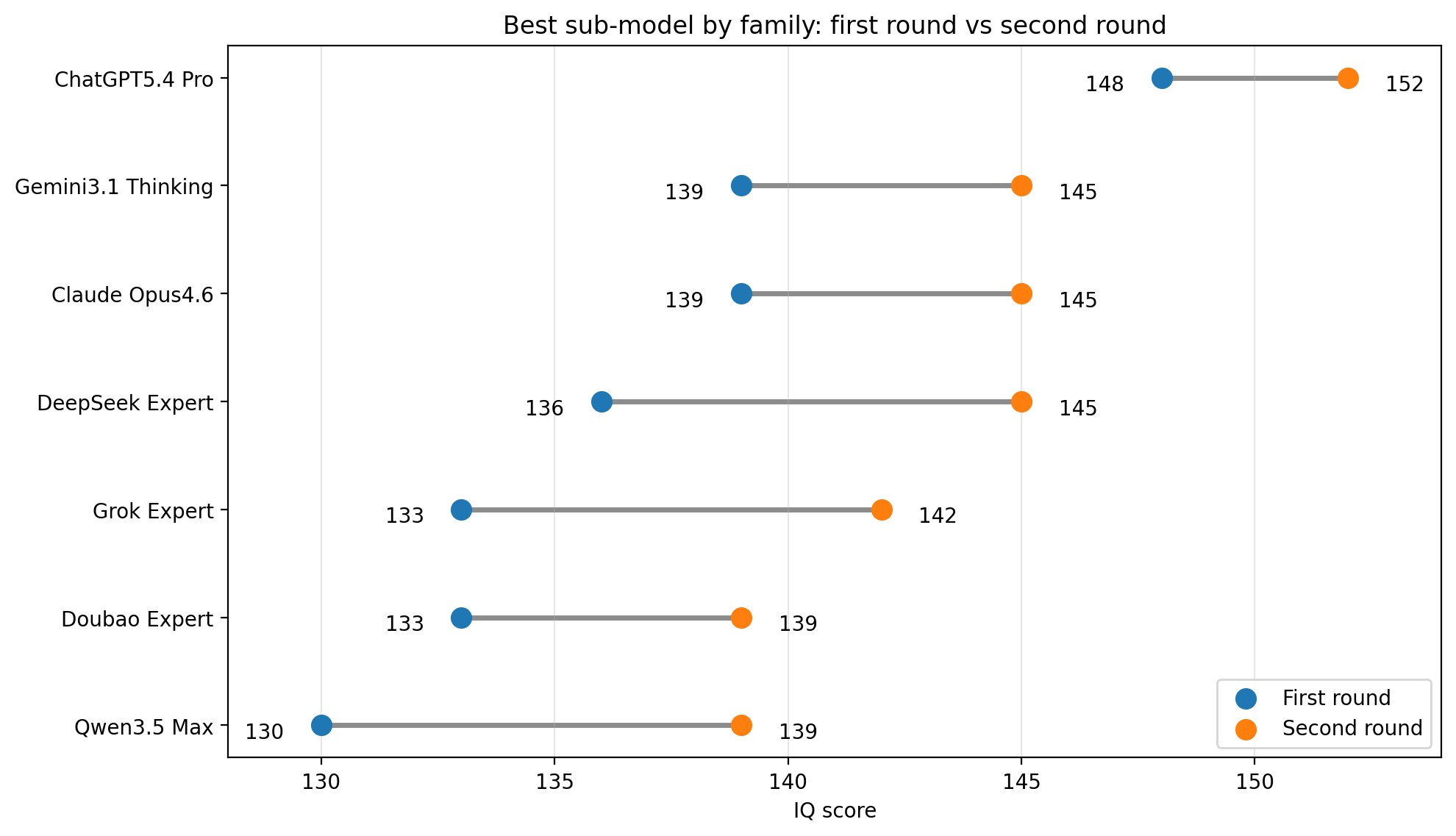
GPT really stands alone.
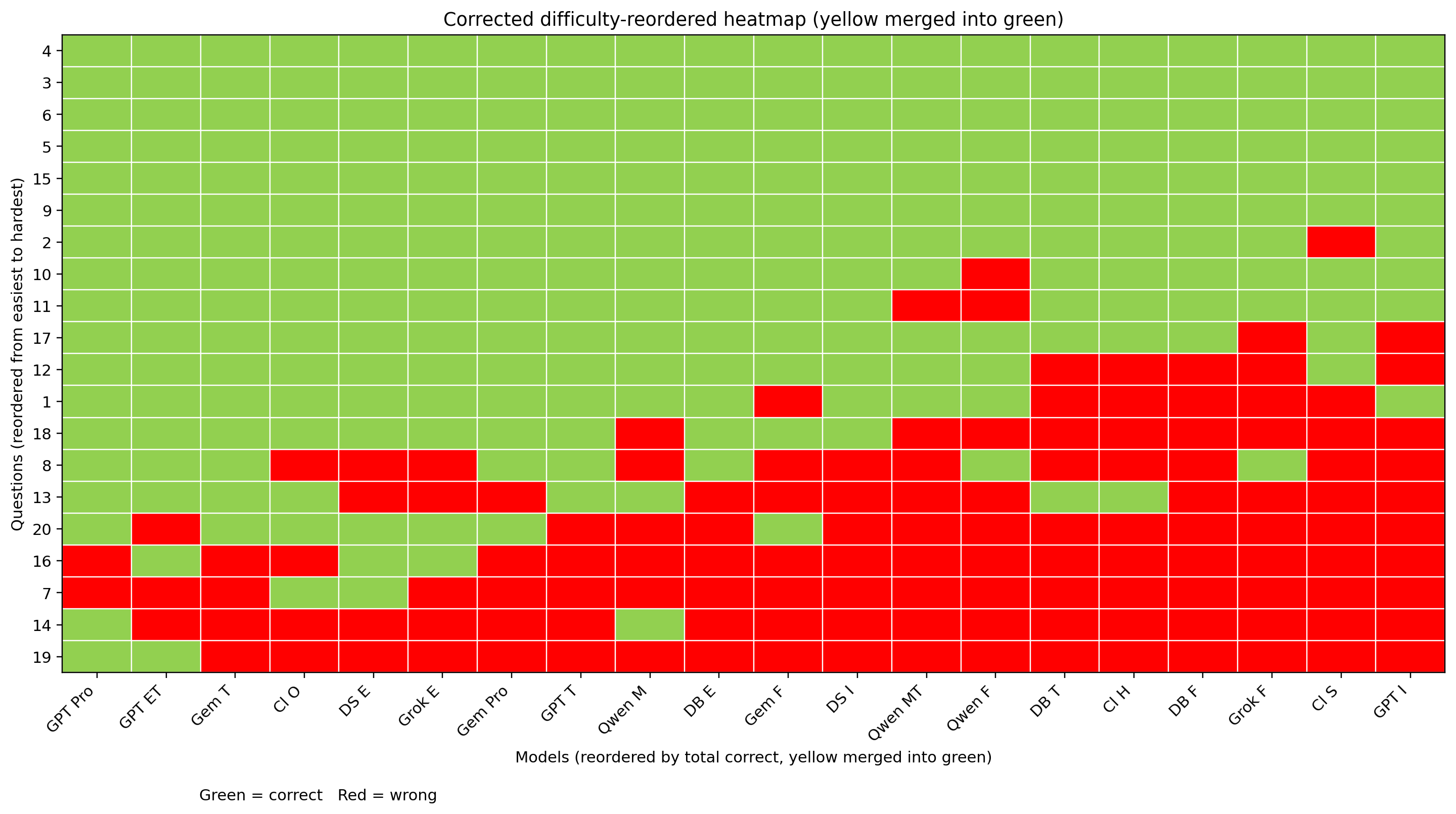
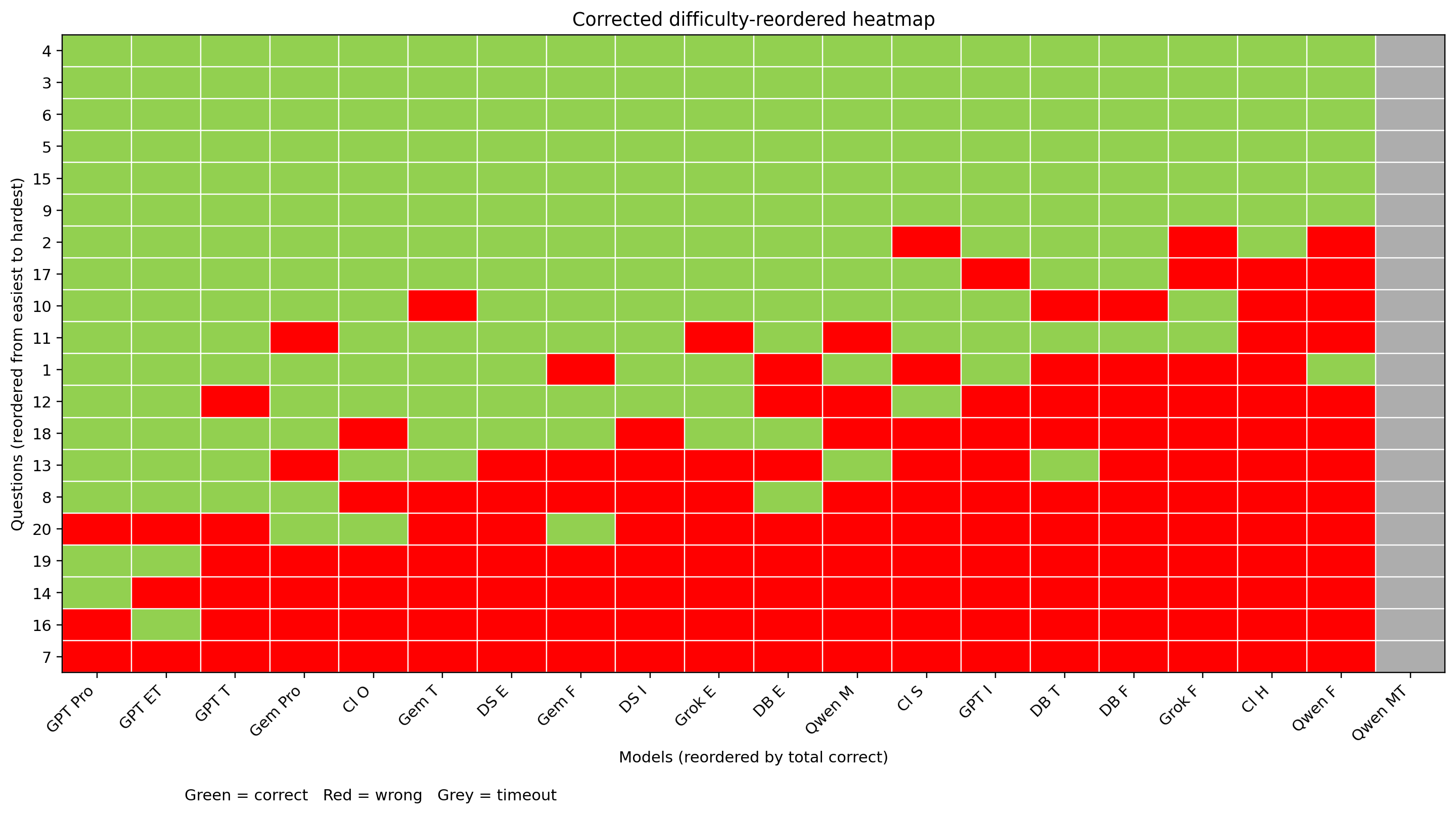
Heatmap of the first-round test, with questions and models sorted by correctness rate:
Heatmap of the retest, with questions and models sorted by correctness rate:
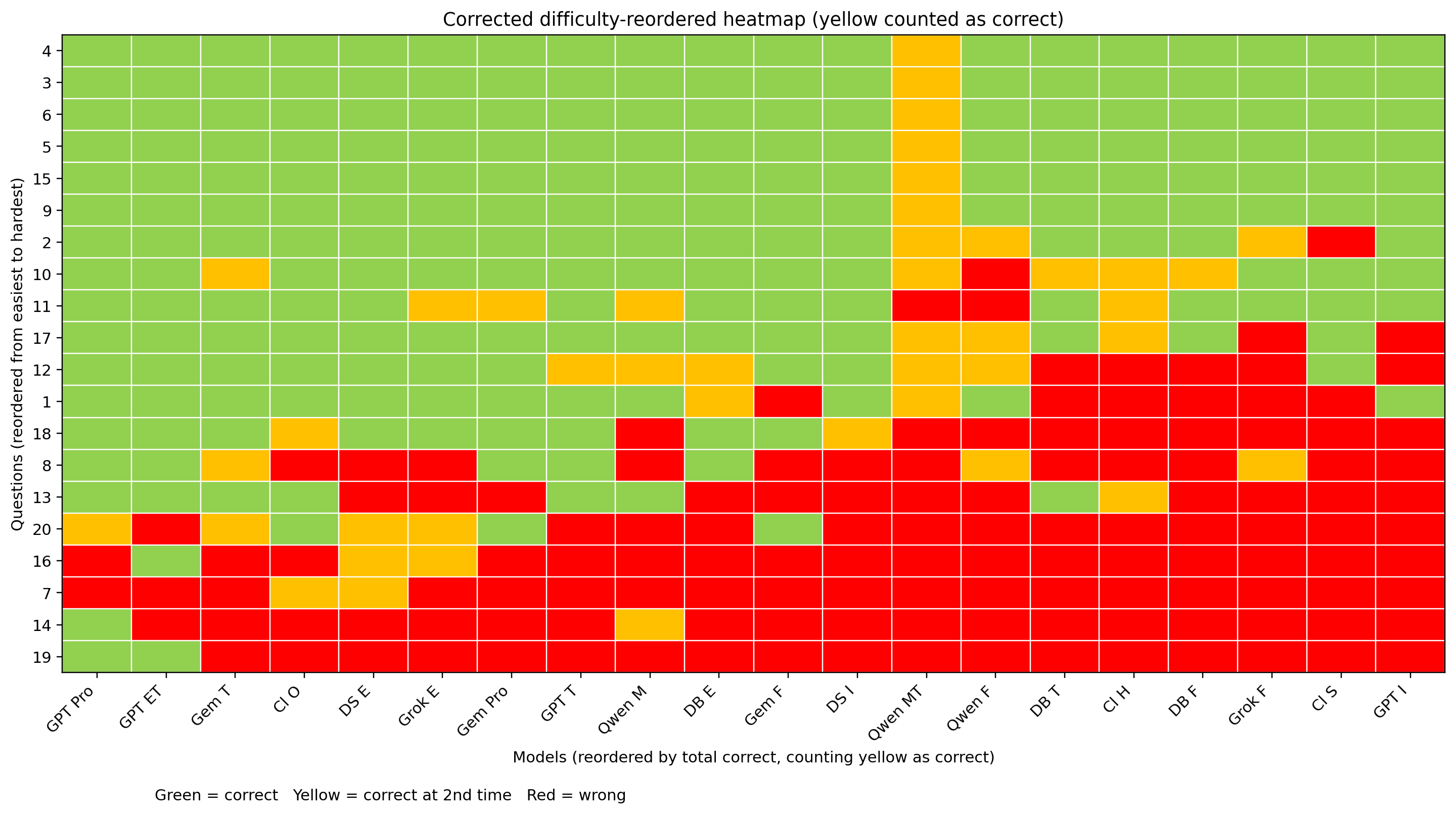
Heatmap of the retest with second-round-correct answers also merged into green: