五八——LLM 数字智商测试
现在网上已经有了一些针对 LLM 的智商评测,比如 https://trackingai.org/home 列举了国内外知名 LLM 的智商测试结果(例如公开的 Mensa Norway 和一名 Mensa 成员的私下题库)。然而,Mensa Norway 的题目基本上以图形推理为主,如果能够了解 LLM 在数字推理能力的表现,也是有一定益处的。
测试题目、模型与方法论
本文选取知名度不如门萨(这意味着被数据集收录的概率较低),但仍具有一定参考价值的 NUMERUS BASIC 数字推理测试 https://free.ultimaiq.net/numerus_basic.htm 。我个人怀疑这个测试给出的判分偏高,但用于比较 LLM 间的相对能力还是有一定价值。
这里我打算选取以下模型作为实验对象:
ChatGPT 5.3/5.4 Thinking (Standard, Extended)/5.4 Pro (Extended)(Web)Gemini 3 Flash/Thinking/3.1 Pro(Web)Claude Haiku 4.5 (Extended)(Web)Sonnet 4.6/Opus 4.6 Thinking(Antigravity)Grok 4.20 Fast/Expert(Web,Heavy 太贵买不起)Deepseek Instant (DeepThink)/Expert (DeepThink)(Web)Doubao Fast/Thinking/Expert(Web)Qwen3.5 Flash/Max/Max-Thinking(Web)
也就是一共 20 种不同模型配置。
为了尽量平衡测试的工作量,并最大限度发挥模型的最大潜力,本文将采取以下测试策略:
- 将 NUMERUS BASIC 的全部 20 道题目以一条消息的形式发送。得到初始答题结果。
- 对于第二次追加测试,如果先前该模型做错,新开对话将这些错题逐一发送,得到修正后的答题结果。
- 测试的提示词如下:
Please fill in the location of the question mark:
1) 1, 1, 1, 2, ?, 2
2) 1, 2, 4, 5, ?
3) -1, 5, 11, ?
4) 0.5, 2, ?, 32
5) 1, 3, 4, ?, 11
6) ?, 1, 3, 6, 10
7) 1, 10, 110, 1101, ?
8) 123, 354, 897, ?
9) 5, 10, 20, 35, ?
10) 2, 4, 12, ?, 72
11) 123, 451, ?, 512
12) 510001, 401010, 300200, ?
13) 11, 32, 54, 78, ?
14) 24, 16, 25, 66, ?, 36
15) 1/2, 3/4, 7/8, ?
16) 1/2, 3/2, 5/6, ?
17) 77, 49, 36, 18, ?
18) 135, 791, ?, 151
19) 138, 257, ?, 132
20) 123, ?, 789, 211101
Write your answers in a row using space to separate each other.
You CANNOT search the Internet, do these problems independently.
初测结果
第一次的测试结果如下:
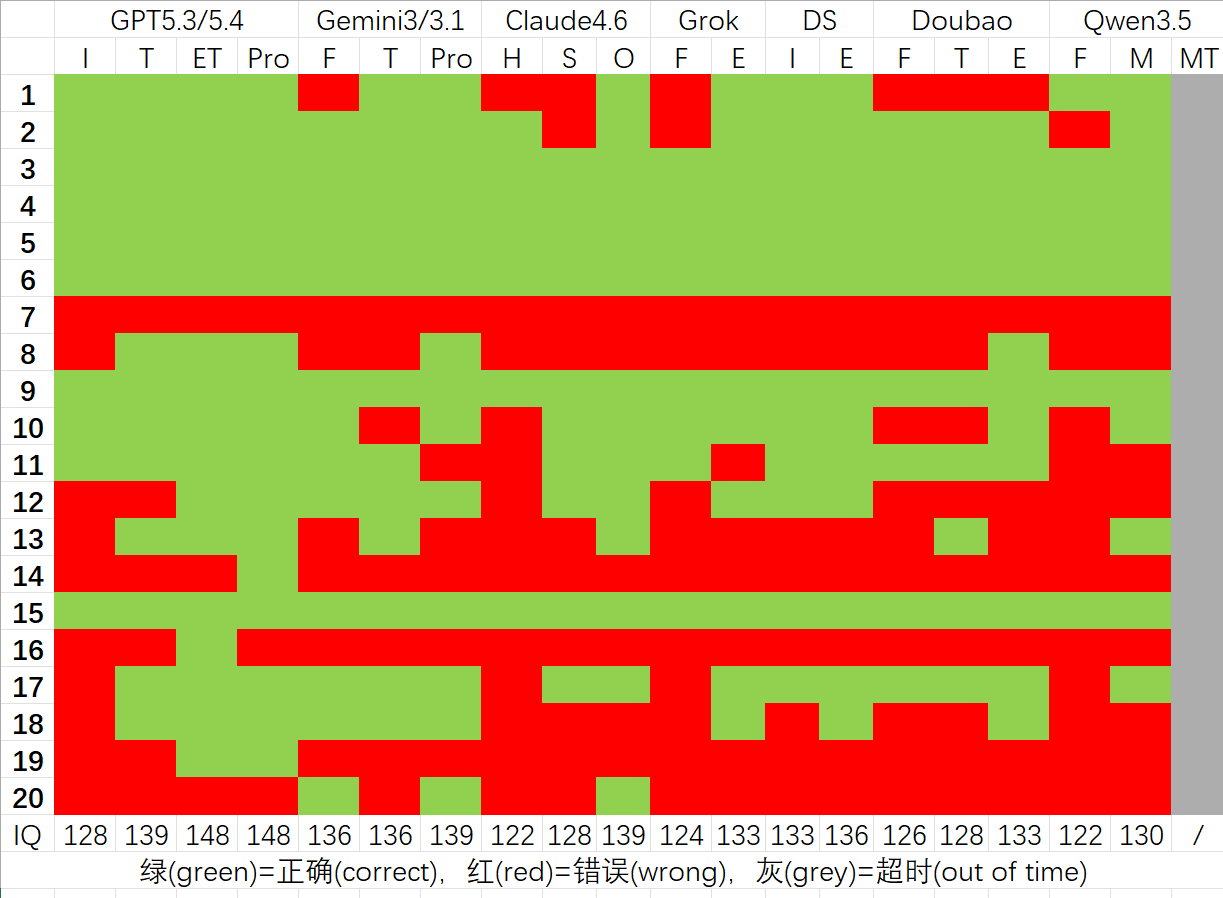
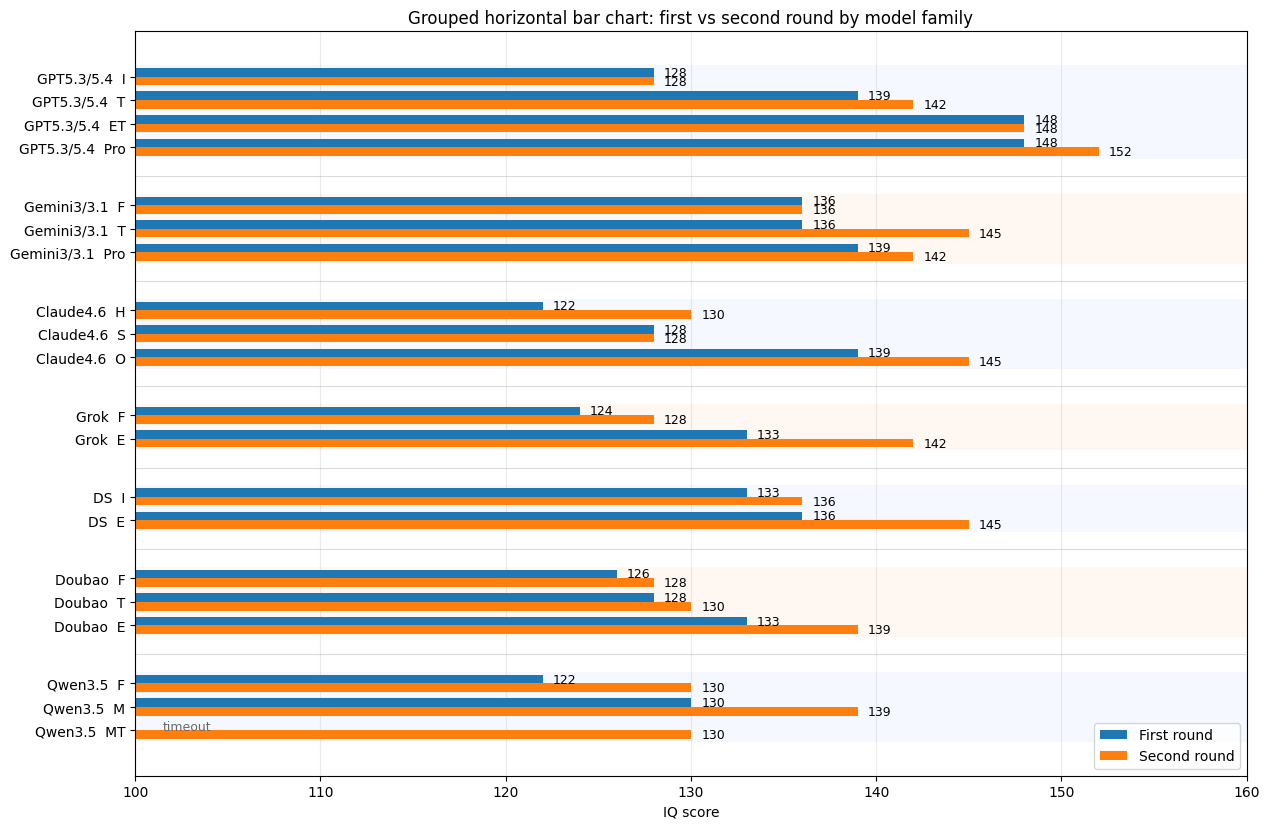
我们可以得到一些结论:
- GPT 相对于其他 LLM 断崖式领先。
- 答题正确率(智商分数)与思考时间正相关。
- 国外 GPT>>Gemini>Claude,国内 Deepseek>Doubao>Qwen。Grok 由于没拿到价值 $300 的 Heavy 账号,因此不好直接比较。
- 考虑成本问题,国产 LLM 基本上可以与国外的 LLM 抗衡了(GPT 除外)。
同时也有一些有趣的观察:
- 耗时最长的是 Deepseek 开启深度思考的 Expert,20 道题一共花了 4998s。
- 千问思考超过 600s 系统就会判定超时并硬中断对话,这相当不友好;而 Deepseek 会选择给一个继续按钮,在推理成本和用户体验达到一个平衡。
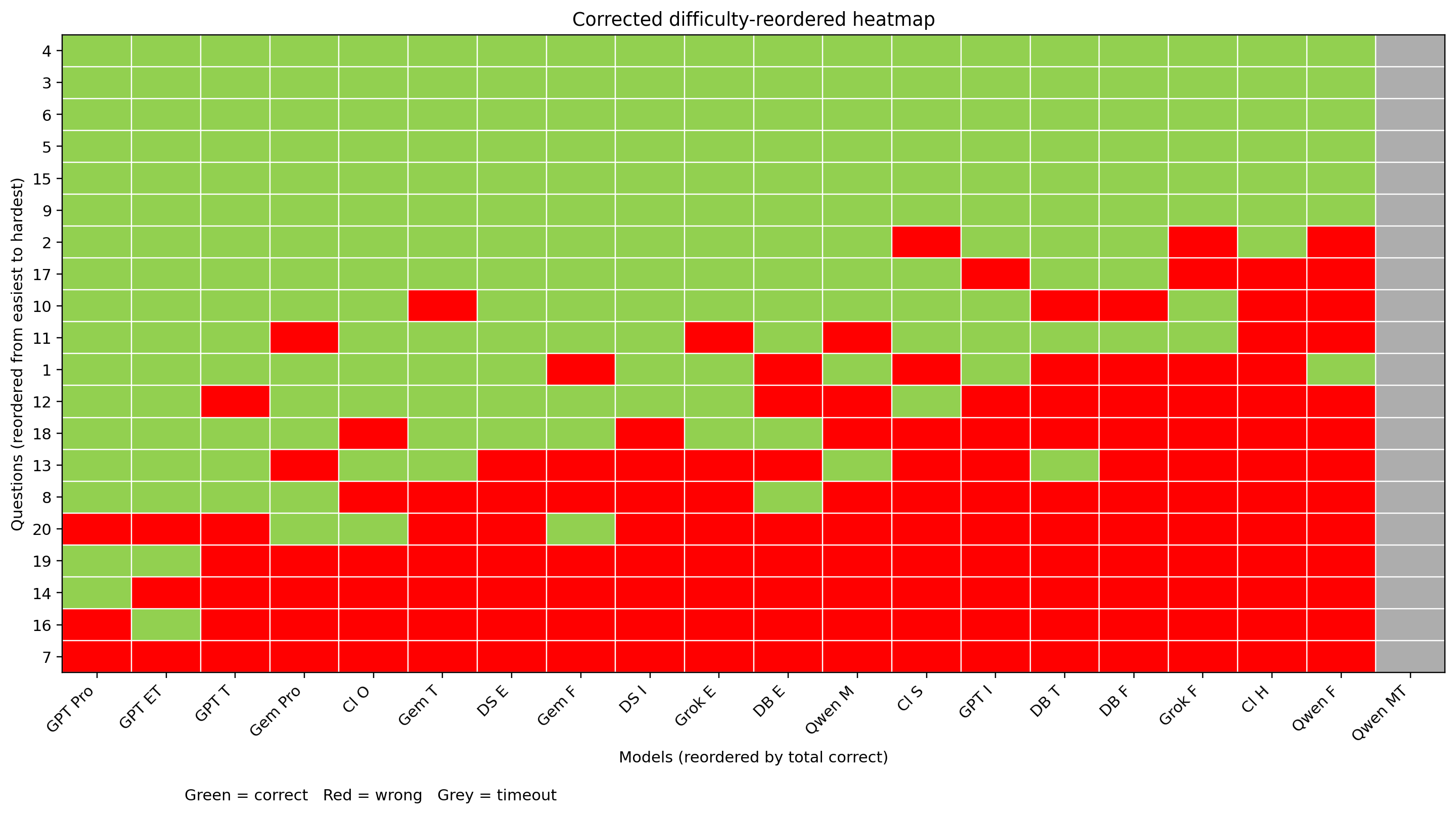
- 对于 LLM 来说,最难的题目是第 7 题,而从人类角度看 14 题是最难的(如果你搜到了那个满分答案解析)。
- 千问不太老实,隔几道题就要使用
You CANNOT search the Internet, do these problems independently.提示词,它才不会调用搜索引擎。
复测结果
复测后的修正答题结果如下,个人认为应该是各模型的上限能力:
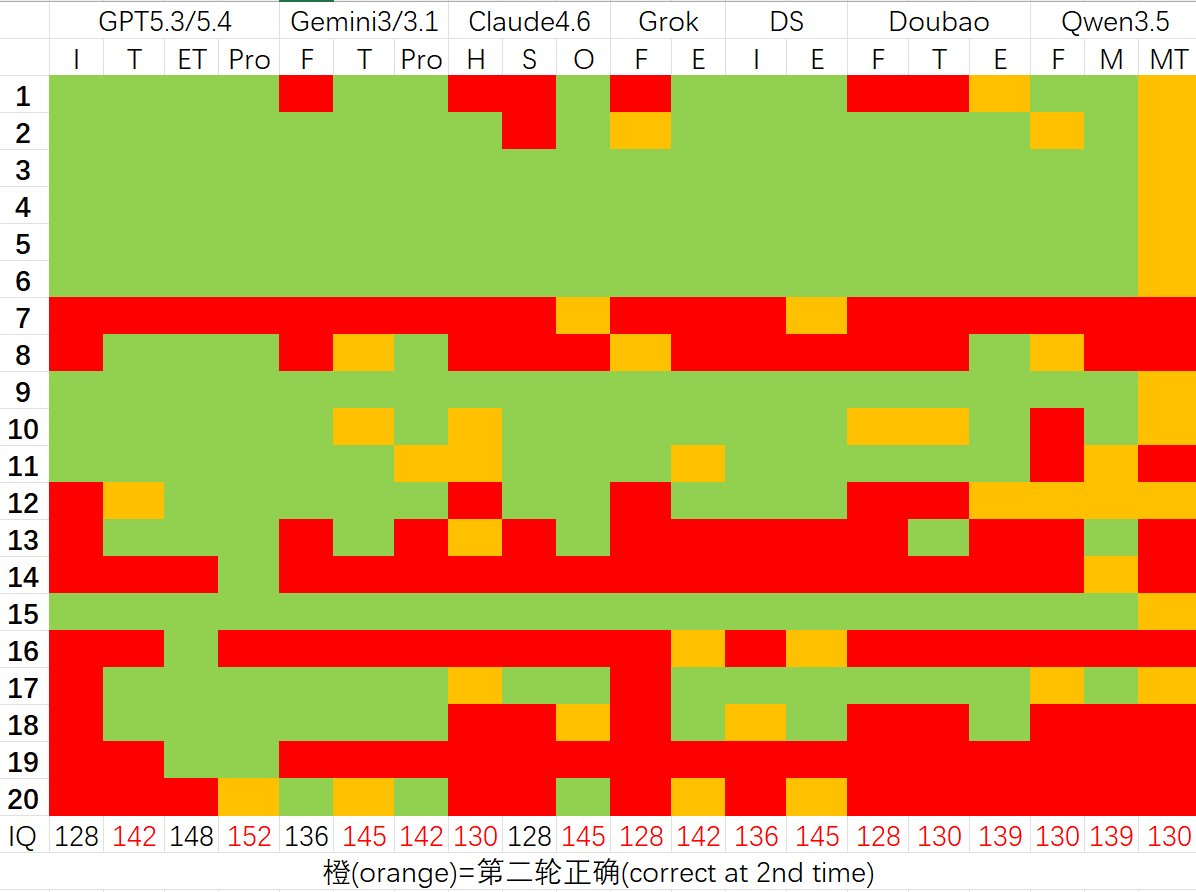
可以得出以下结论:
- GPT 相对于其他 LLM,仍然是断崖式领先,甚至 pro 版本 IQ 超过了 150.
- 对于绝大多数模型,把任务拆分来做还是有益于提高正确率。
- 国外 GPT>>Gemini>Claude,国内 Deepseek>Doubao≈Qwen.
- Deepseek Expert 已经达到了 Gemini/Claude 最好模型的水平——只不过有时候思考时间太长了。
另外一些有趣的观察:
- grok Fast 感觉非常喜欢说胡话——这非常符合 Musk 嗑药之后的风格。

- deepseek Expert(也就是传说中的 V4 版本)在思考 14 题时开始背起了圆周率,等了一个下午后,我尝试随便截取中的一段,放到这个网站里看看是不是在 Pi 的前 20 亿位——结果答案是否定的,就代表 deepseek 背错了。

- 千问 Flash 经常喜欢输出一些循环的结果,然后被系统强行停止(这与之前 600 秒超时异曲同工)。
- 千问 Max 用错误的思路蒙对了对于人类来说最难的 14 题。
- 13 题的答案有争议,许多 ai 指向的另一个答案都有道理(包括我第一次做也是那个答案)。但为了确保公平性,我选择按照网站结果给分。
可视化
所有参与模型修正前后的成绩比较:
最好模型修正前后的成绩比较:
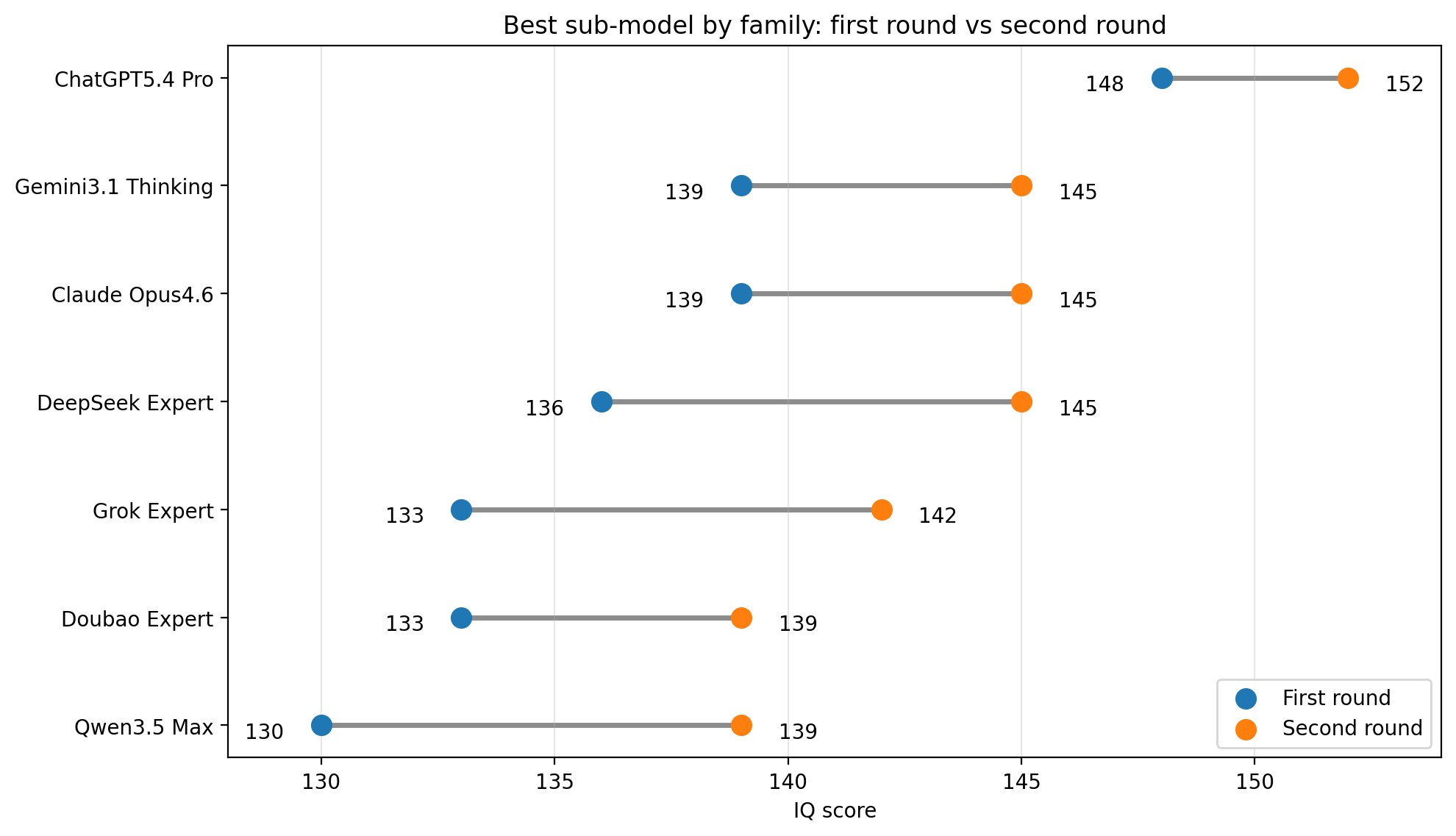
GPT 还是独树一帜啊。
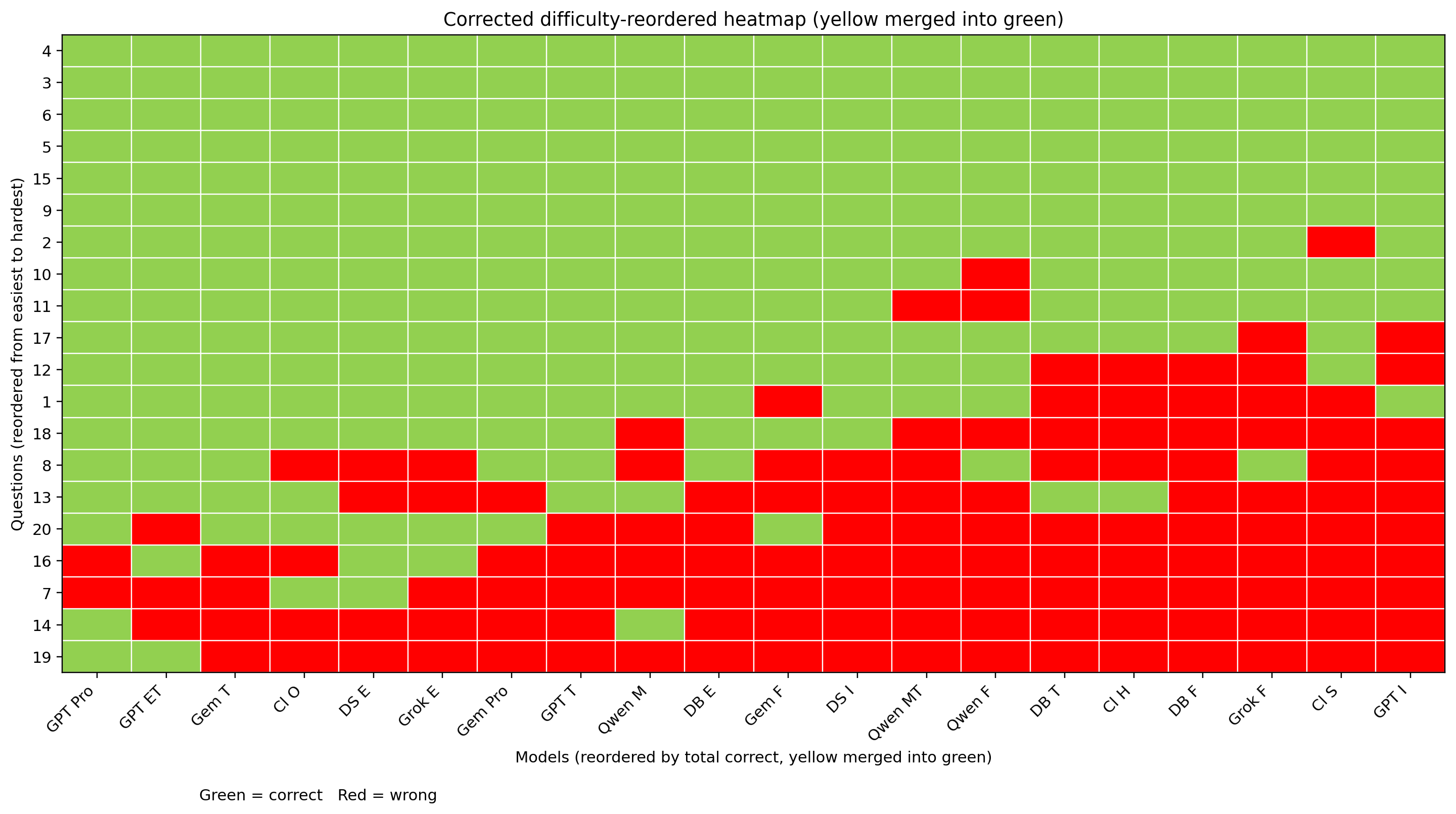
按照题目正确率与模型正确率排序的热力图(首测):
按照题目正确率与模型正确率排序的热力图(复测):
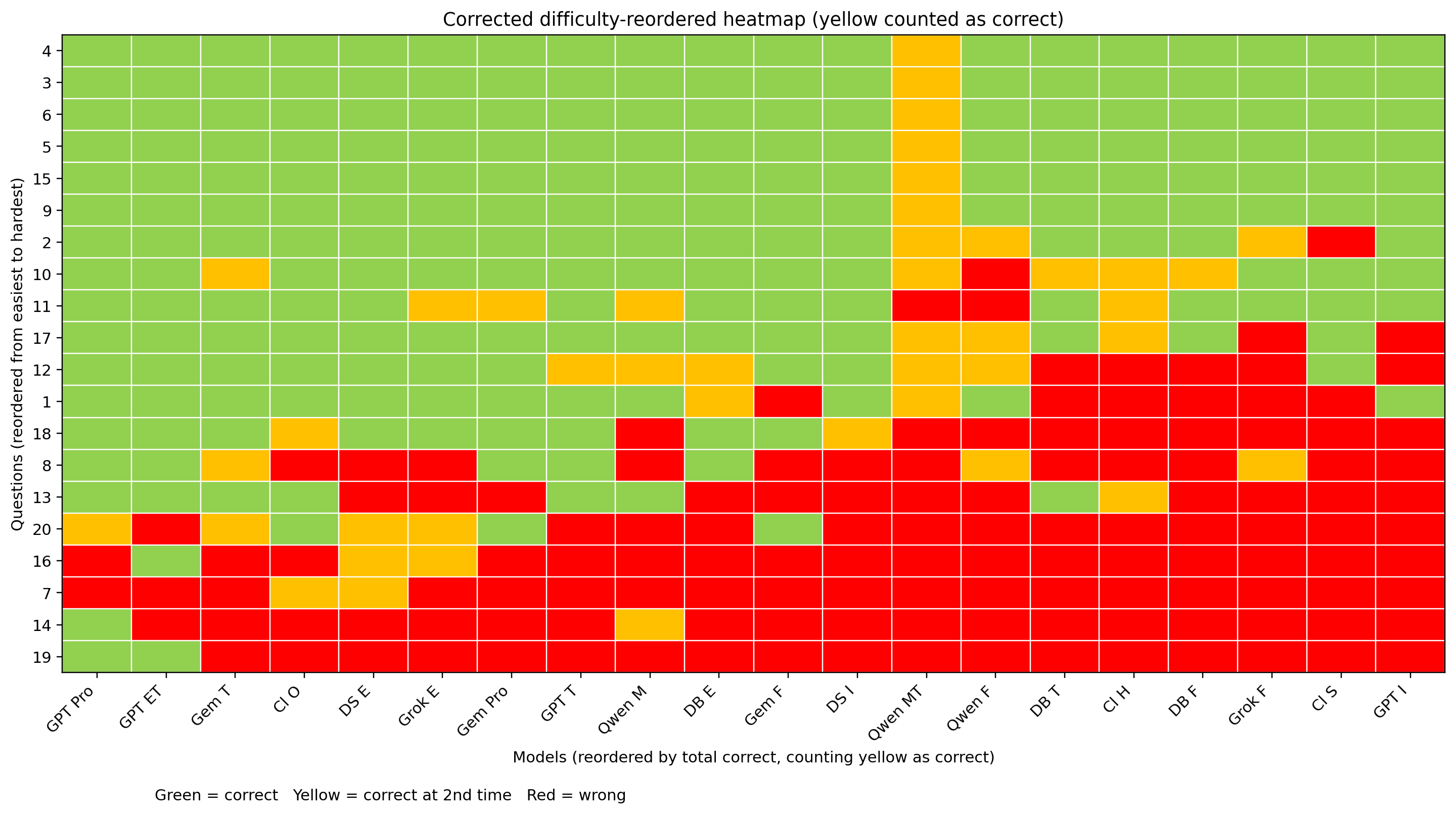
按照题目正确率与模型正确率排序的热力图(将复测正确也归入绿色):